Current Projects
|
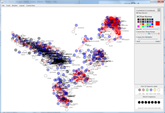
Large-Scale Semantic Modeling (funded by NSF and Google)
Collaborators: Brendan Johns, Brent Kievit-Kylar, Jon Willits, Ken McRae, Gabriel Recchia, Pentti Kanerva Most existing models of semantic learning (e.g., Latent Semantic Analysis) are limited in their ability to scale to large amounts of data. Although the models are compared to behavioral data from college-level participants, they tend to be trained on less linguistic experience than the average 2-year old child experiences. We are working on a variety of random accumulation models of semantic learning that naturally scale to continuous streams of human-scale linguistic data. They are also flexible enough to integrate multiple streams of information into a single knowledge representation, giving them considerably more power from a much simpler learning mechanism. Sample publications: Jones, M. N., Willits, J. A., & Dennis, S. (2015). Models of semantic memory. In J. R. Busemeyer & J. T. Townsend (Eds.) Oxford Handbook of Mathematical and Computational Psychology. Jones, M. N., & Mewhort, D. J. K. (2007). Representing word meaning and order information in a composite holographic lexicon. Psychological Review, 114, 1-37. |
|
Lifelong Semantic Learning (funded by IU EAR)
Collaborators: Willa Mannering There has been a recent surge of interest in AI systems that learn continuously in dynamic shifting environments (think augmented reality, self-driving cars, etc.). One system that nature gave us that is quite adept at this is the child. Redesigning machine learning systems from the perspective of human learning science is the major thrust behind out recent Emerging Areas of Research Institute titled Learning: Machines, Brains, & Children. (also see: Making a thinking machine). A specific area of interest to our lab group is in modeling the mechanisms that humans use to adapt semantic representations continually in response to shifts in environmental regularities. Modern neural networks, such as word embedding or transformer networks, have great difficulty learning new concepts while preventing the new learning from overwriting previous learning. For example, we have recently demonstrated the strong effect of catastrophic forgetting in word embedding models as a function of the order in which word senses are encountered due to their error-driven learning architecture. In contrast, Hebbian learning systems, such as my original BEAGLE model, are largely immune to catastrophic forgetting. Sample publications: Mannering, W. M., & Jones, M. N. (2019). Insulating distributional semantic models from catastrophic interference. Proceedings of the 41st Annual Meeting of the Cognitive Science Society. Wulff, D. U., De Deyne, S., Jones, M. N., Mata, R., & the Aging Lexicon Consortium. (2019). New perspectives on the aging lexicon. Trends in cognitive sciences. Dachapally, P. R., & Jones, M. N. (2018). Catastrophic interference in neural embedding models. Proceedings of the 40th Annual Meeting of the 40th Annual Meeting of the Cognitive Science Society. |

|
Experiental Optimization
Collaborators: Brendan Johns, Doug Mewhort The vast majority of the literature on semantic memory assumes that all native speakers share the same general world knowledge, with little attention paid to individual differences in semantics. When it comes to modeling semantic tasks, this requires us to build many free parameters into the process models that operate on semantic structure to explain variance across tasks, materials, and individuals. However, complexity in the process models may be unnecessary. It is more plausible that two different humans have learned from different experiences, or that different memory subsets are recruited in different tasks. We have recently demonstrated this with a process we call Experiental Optimization. Simply put, there may be no need to assume complex process parameters in say a diffusion model of semantic decision, if we simply allow individual differences into the learning mechanism. In addition, the Experiental Optimization algorithm can be inverted: Given a task you want a human to be expert at, it can reverse engineer the optimal set of reading materials to build a memory representation that is optimal for the desired task. Sample publications: Johns, B. T., Jones, M. N., & Mewhort, D. J. K. (2019). Using experiential optimization to build lexical representations. Psychonomic Bulletin & Review. Johns, B. T., Mewhort, D. J. K., & Jones, M. N. (2019). The role of negative information in distributional semantic learning. Cognitive Science. |
|
Integrating Linguistic and Perceptual Information in Models of Lexical Semantics (funded by NSF and Google)
Collaborators: Brent Kievit-Kylar, Jon Willits, Brendan Johns, Melody Dye, Gabriel Recchia Humans learn the meanings of words and larger discourse units from repeated experience with both linguistic and perceptual information. However, current models of semantic learning and representation focus only on linguistic structure, ignoring perceptual experience, and learn at a scale that is far smaller than the data experienced by humans. A major limitation to the development of perceptually grounded semantic models is simply a lack of structured data coding the perceptual referents of words. Under our NSF Semantic Pictionary Project, we have developed a suite of online games that are designed to crowdsource human coding of perceptual information. We have developed several computational models that integrate perceptual and linguistic information, and are currently conducting empirical work to constrain between the possible models. These systems can be extremely useful, both for theoretical understanding of learning, and as applied algorithms for sensor-based systems to integrate sensory information with linguistic information (e.g., any smartphone). But in addition to systems that see and hear, even simple internet search depends on perceptual integration. The human doing the search is basing his/her query on a lifetime of experience with perceptual and linguistic knowledge, but the machine system doing the information retrieval knows only how concepts are related based on statistical information in language. No matter how good the machine learning algorithm, it is missing a fundamental amount of embodied information that changes the entire memory space. Sample publications: Johns, B. T., & Jones, M. N. (2012). Perceptual inference from global lexical similarity. Topics in Cognitive Science, 4:1, 103-120. Kievit-Kylar, B., & Jones, M. N. (2011). The semantic Pictionary project. In L. Carlson, C. Hölscher, & T. Shipley (Eds.), Proceedings of the 33rd Annual Conference of the Cognitive Science Society (pp. 2229-2234).Austin, TX: Cognitive Science Society. Riordan, B., & Jones, M. N. (2011). Redundancy in perceptual and linguistic experience: Comparing feature-based and distributional models of semantic representation. Topics in Cognitive Science, 3:2, 1-43. |

|
Retrieval-Based Semantic Models
Collaborators: Randy Jamieson, Brendan Johns, Matt Crump, Jack Avery Virtually all models of semantic memory are prototype theories in that they collapse multiple distinct contexts in which a word is experienced into an aggregate point or representation. This is in stark contrast to work in categorization research, however, which has largely converged on the superiority of exemplar-based models over prototype models. A recent focus of our lab has been to develop exemplar-based semantic models. In these models, there is no semantic memory per se; only episodic memory traces are stored. Semantic memory is an emergent property of retrieval from episodic memory. More than just a theoretically distinct take, our exemplar-based models can apply nonlinear activation over exemplars that match a cue, allowing them to easily comprehend both dominant and subordinate senses of homonyms (e.g., bank: finance, river, plane), which are averaged out in the representations of classic models and modern neural networks. The success of these models suggest that human semantic memory may not be memory at all—rather it may be constructed on the fly as an artifact of retrieval mechanisms operating on episodic memory. Sample publications: Jones, M. N. (2018). When does abstraction occur in semantic memory: Insights from distributional models. Language, Cognition and Neuroscience. Jamieson, R. K., Johns, B. T., Avery, J. E., & Jones, M. N. (2018). An instance theory of semantic memory. Computational Brain & Behavior. |
|
Understanding linguistic and semantic development via naturalistic child-directed data (funded by NIH)
Collaborators: Jon Willits, Jessica Montag, Linda Smith, Fatemeh Asr What constraint does the statistical environment place on child language learning, and how much can a simple learning system acquire without positing innate rules? Our knowledge of child language learning is making huge advancements with the availability of large-scale linguistic and video-based data from children in their natural environments. We are developing and testing the ability of relatively simple distributional models of lexical acquisition. Although the data that young children experience seem very impoverished and noisy, these simple systems surprise us by naturally learning increasingly complex conceptual relations and linguistic structures that correspond well to known developmental trends in laboratory studies. A formal account of child conceptual learning is a first required step to then begin to understand developmental disorders as an interaction between learning mechanisms and the statistical structure of experience, offering potential clues to training regiments that will be optimal for learning disabilities. Sample publications: Montag, J. L., Jones, M. N., & Smith, L. B. (2018). Quantity and diversity: Simulating early word learning environments. Cognitive Science. Asr, F. T., Willits, J. A., & Jones, M. N. (2016). Comparing predictive and co-occurrence based models of lexical semantics trained on child-directed speech. Proceedings of the 37th Meeting of the Cognitive Science Society. Montag, J. L., Jones, M. N., & Smith, L. B. (2015). The words children hear: Picture books and the statistics for language learning. Psychological Science. |

|
Retrieval Operations from Episodic and Semantic Memory
Collaborators: Brendan Johns, Thomas Hills, Peter Todd, Janelle Szary, Nancy Lundin With large-scale simulations of human semantic memory, we can then turn to the task of trying to better elucidate the mechanisms that humans use to search and retrieve information from memory within the constraints of a task. A large amount of work from our lab has looked at association and fluency tasks—the former is essentially you saying what comes to mind first when I say “dog,” and the latter is you continuously producing exemplars from memory when I probe you with a category cue (e.g., “name all the animals you can in a minute”). Both tasks have important theoretical and clinical implications. Our research has found that humans search memory using mechanisms that seem to be repurposed by evolution from the mechanisms that we use to optimally search for resources in spatial settings (e.g., foraging for food). We also have a great amount of interest in better understanding human mechanisms for recognition and recall tasks, especially simulating the bizarre patterns that come from human false memories and memory illusions. See: People forage for memories in the same way birds forage for berries, Science Daily. Sample publications: Jones, M. N., Hills, T. T., & Todd, P. M. (2015). Hidden processes in structural representations: A reply to Abbott, Austerweil, & Griffiths. Psychological Review, 122, 570-574. Hills, T. T., Todd, P. M., & Jones, M. N. (2015). Foraging in semantic fields: How we search through memory. Topics in Cognitive Science, 7, 513-534. Hills, T. T., Jones, M. N., & Todd, P. T. (2012). Optimal foraging in semantic memory. Psychological Review, 119, 431-440. |

|
Echoes of Cognitive Mechanisms in Big Data
Collaborators: Rick Dale, Dave Vinson, Brendan Johns, Mike Mozer Cognitive theory has become even more important in the age of big data—our theories are based on decades of experimental research, and they help us focus on what causal patterns to look for in big data. Model-based data mining takes the causal models that are well understood in the laboratory and uses them to identify patterns in big data that would have been impossible to identify with strictly data-driven data mining. Plenty of examples are out there in consumer behavior: Context and sequence effects in decision making in the laboratory are used to optimally design products for online merchants such as Amazon to change the things we buy. We have recently been using very basic context effects in identification and categorization in the laboratory (contrast and assimilation effects) to look at human product reviews on Amazon and Yelp. Modern recommender systems are at an upper limit because the ratings that humans give for the absolute magnitude of an experience are cognitively biased with sequential information. Put simply, more of the variance in your decision of how much you liked a movie you just watched is based not on the actual quality, but on the relative difference between it and the previous movie you saw. Very basic perceptual sequence effects contaminate all ratings data, and they need to be properly decontaminated with cognitive models so that recommender systems can make more accurate predictions of the absolute magnitude of the experience. Sample publications: Vinson, D. W., Dale, R., & Jones, M. N. (2019). Decision contamination in the wild: Sequential dependencies in online review ratings. Behavior Research Methods. (Special issue: "Beyond the Lab: Using Big Data to Discover Principles of Cognition") Jones, M. N. (2017). Developing cognitive theory by mining large-scale naturalistic data. In M. N. Jones (Ed.), Big Data in Cognitive Science. New York: Taylor & Francis. Mozer, M. C., Pashler, H., Wilder, M., Lindsey, R. O., Jones, M., & Jones, M. N. (2010). Decontaminating human judgments by removing sequential dependencies. In J. Lafferty & C. Williams (Eds.). Advances in Neural Information Processing Systems, 23. Cambridge, MA: MIT Press. |
|
Contextual Diversity in Lexical Learning
Collaborators: Brendan Johns, Melody Dye, Gabriel Recchia Learning to organize the mental lexicon is one of the most important cognitive functions across development, laying the fundamental structure for future semantic learning and communicative behavior. Building a lexicon requires at minimum organization such that 1) words that are more likely to be needed are more highly accessible, and 2) words that are similar in meaning are proximal in mental space. Classic accounts of word learning have assumed that humans are sensitive to frequency information (repetition) during learning: The more times a word is repeated, the stronger its memory trace and the closer it becomes to semantically similar words. However, a small flurry of recent research suggests that it is not frequency but, rather, diversity in a word’s context that is the important source of statistical information humans attend to when learning lexical organization. It is currently unclear whether this diversity is due to the number of contexts in which a word occurs, or whether the information overlap of the contexts is the important factor. Further, it is unknown whether the same type of statistical diversity underlies both lexical access and lexical similarity. For the past several years, our lab has been have been exploring this line of research with a combination of simulations and experimental work. The results of this work is pointing to a construct that we call “semantic diversity” as the raw statistical source of learning that humans are sensitive to. We have found that models that encode a new word’s context with a strength relative to the novel information content of the surrounding context (that is, how much of what is being learned is not already predictable from the existing structure of memory) give a better approximation of human behavioral data. These ideas are also already being used in speech therapy, and as part of the Oxford Reading Initiative in the UK. Sample publications: Jones, M. N., Dye, M., & Johns, B. T. (2017). Context as an organizational principle of the lexicon. In B. Ross (Ed.), The Psychology of Learning and Motivation, 67:43. Johns, B. T., Dye, M. W., & Jones, M. N. (2015). The influence of contextual diversity on word learning. Psychonomic Bulletin & Review. Johns, B. T., Gruenenfelder, T. M., Pisoni, D. B., & Jones, M. N. (2012). Effects of word frequency, contextual diversity, and semantic distinctiveness on spoken word recognition. Journal of the Acoustical Society of America, 132:2, EL74-EL80. |

|
Clinical Data Mining with Cognitive Models
Collaborators: Brendan Johns, Vanessa Taler, Jon Willits, David Pisoni, Brian O’Donnell, Paul Lysaker, David Kareken, Fred Unverzagt, Andy Saykin Along with our collaborators, our lab is very interested in what novel insights may come from applying cognitive models of retrieval and semantic memory to clinical data. A main current focus is on discriminating normal cognitive decline from dementia: specifically Alzheimer’s Disease and its supposed precursor Mild Cognitive Impairment (MCI). Episodic memory impairments are thought to be a hallmark of dementia (e.g., forgetting where the car was parked or your daughter’s name), but this is largely because episodic memory is easy to quantify in neuropsychological testing (e.g., n-back paradigms). Recent research has demonstrated that semantic memory may be particularly impaired by early neurodegeneration that accompanies MCI, but “meaning” has previously been a very difficult thing to quantify. Our semantic models and retrieval models from the above basic research lend themselves perfectly to the quantification of semantic behavior, and allow us to determine the cognitive parameters that are most likely to be culprit in these disorders. We are also applying the same models to data from Schizophrenia patients and prelingually deaf children with cochlear implants. Sample publications: Willits, J. A., Rubin, T., Jones, M. N., Minor, K. S., & Lysaker, P. H. (2018). Evidence of disturbances of deep levels of semantic cohesion within personal narratives in schizophrenia. Schizophrenia Research. Minor, K. S., Willits, J. A., Marggraf, M. P., Jones, M. N., & Lysaker, P. H. (2018). Measuring disorganized speech in schizophrenia: automated analysis explains variance in cognitive deficits beyond clinician-rated scales. Psychological Medicine. Johns, B. T., Taler, V., Pisoni, D. B., Farlow, M. R., Hake, A. M., Kareken, D. A., Unverzagt, F. W., & Jones, M. N. (2017). Cognitive Modeling as an Interface between Brain and Behavior: Measuring the Semantic Decline in Mild Cognitive Impairment. Canadian Journal of Experimental Psychology. |
Completed Projects

|
Model-Based Guided Retrieval Practice Systems (funded by IES)
Collaborators: Jeff Karpicke, Brent Kievit-Kylar, Phil Grimaldi In collaboration with Jeff Karpicke’s Cognition and Learning Lab at Purdue University, the CC Lab is working to build holographic semantic models into an overall personalized learning platform for retrieval-based learning (RBL). While most education and training scenarios use repeated study to encode and retain information, recent research in learning sciences has demonstrated that active reconstruction of knowledge in the form of RBL can lead to an up to three times greater likelihood of long-term retention. The key is to have tailored feedback for the learner during RBL, which is not possible in a traditional classroom or MOOC setting, and is the likely reason that one-on-one human tutoring is the most effective form of instruction known. Using the BEAGLE model as a flexible and generalizable feedback engine (along with NLP techniques), we have designed an intelligent RBL software platform that is suitable for e-learning scenarios, classrooms, and industry training problems. The system is currently in the development and beta testing phase, and we expect to have it deployed in elementary classrooms by 2016. |
|
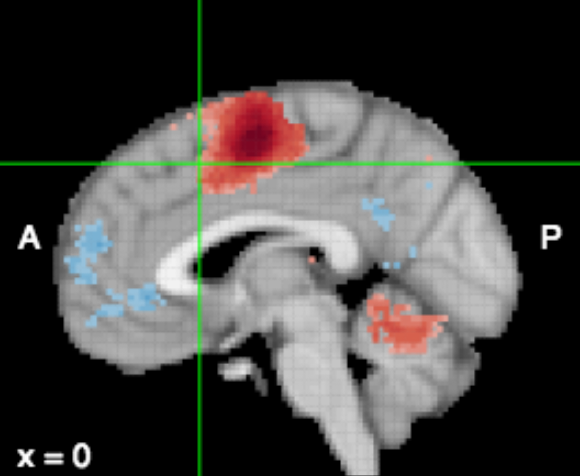
Large-Scale Automated Synthesis of Human Functional Neuroimaging Data (funded by NIH)
Collaborators: Tal Yarkoni, Tim Rubin, Russell Poldrack, Tor Wager Neurosynth is a multisite project aimed at developing a novel platform for large-scale, automated synthesis of functional magnetic resonance imaging (fMRI) data extracted from published articles. It's a website wrapped around a set of open-source Python and JavaScript packages. Neurosynth lets scientists run crude but useful analyses of fMRI data on a very large scale. My lab’s role in the project is improving the NLP and knowledge discovery algorithms of the system using Hierarchical Bayesian Topic modeling, with the goal of discovering how psychological constructs described in the text of scientific articles correspond with brain activity and with each other. Rubin, T. N., Koyejo, O., Gorgolewski, K. J., Jones, M. N., Poldrack, R. A., & Yarkoni, T. (2017). Decoding brain activity using a large-scale probabilistic functional-anatomical atlas of human cognition. PLOS Computational Biology. Rubin, T., Koyejo, O., Jones, M. N., & Yarkoni, T. (2016). Generalized correspondence-LDA models (GC-LDA) for identifying functional regions in the brain. Advances in Neural Information Processing Systems. Neurosynth Beta Site | Press Release: "Google of the Brain" |

|
Developing Tools to Mine Large-Scale Linguistic Data using Cognitive Models
Collaborators: Jon Willits, Brent Kievit-Kylar, Tim Rubin, Gabriel Recchia, Tal Yarkoni The lab is actively involved in developing open software for large-scale exploration and analysis of linguistic and perceptual data. We have released dozens of open software platforms and tools to assist other researchers in using state-of-the-art semantic models and visualization techniques to search massive textbases for important patterns. We also have fun examples of using semantic models to mine political transcripts, how to name your baby, etc. A few examples are listed below. SemaniCore.org: A web-based one-stop shop for psycholinguistic metrics. We have server-based versions of the major semantic models trained on a variety of corpora for researchers to explore word similarity measures and to calibrate stimuli. SemaniCore is also interfaced with the MRC Psycholinguistc Database, McRae’s feature database, WordNet, and a variety of other orthographic and phonological databases. Word-2-Word: A visualization software that allows users to explore the structure of custom text corpora by displaying graphical networks based on a variety of similarity metrics. Word-2-word affords efficient visual (and quantitative) exploration of text to identify higher-order semantic patterns. See: Kievit-Kylar, B., & Jones, M. N. (2012). Visualizing multiple word similarity measures. Behavior Research Methods, 44, 656-674. |

|
Using cognitive models to identify efficient, secure, and memorable passwords.
Collaborators: Markus Jakobsson, Brent Kievit-Kylar Modern passwords are a pA1n in the A$$. The original idea with a password was to pick something that you could remember and not have to write down, but was rare enough that an adversary couldn’t easily guess it. But as time went on and more and more cat names were used, a battle between entropy and memorability emerged, and memorability lost. Current password rules are engineered to generate passwords that cannot easily be guessed. As an experimental psychologist, I can also tell you that these are the perfect rules to create stimuli that no human will be able to remember. The consequence is that nobody remembers their passwords anymore—we might use a password manager, or unfortunately, write everything down on a sticky note (which kind of defeats the purpose). Most online companies are more concerned with their own liability rather than your security. So you are forced to generate a password that is impossible to remember, very difficult to type, and even if you learned it, you would be forced to use a completely new after about 12 months that bears no similarity to the previous one. Another unfortunate consequence of these rules is that most people tend to reuse their passwords at multiple accounts, which compromises security further. And consider the problem of entering these difficult passwords on a mobile device: “flY2theM0On!” costs 21 clicks on an iPhone, despite having only 12 characters! I’ll spare you the math on information entropy, but basically the modern movement toward passphrases has to do with the fact that there are more possible words than characters to select from, and words are meaningful to us. We want to use a phrase that is easy to remember, but not so common that it can be easily guessed by an adversary. Markus Jakobsson, a leader in online security, has pioneered work with Fastwords: Select a set of three words that uniquely identify a memorable event to you. Entering the authentication response is easy on a mobile device because it can use spellcheck on the response. If you forget your response, the system can probe you with one word to remind you of the story, which then lets you generate the other two. But the coolest thing is that we can apply semantic models to Fastwords. I have been collaborating with Markus to use fuzzy semantic matching based on BEAGLE. Even if you can’t recall the exact words you used originally, the model can allow great flexibility in the words used, knowing the likelihood that you are the person who possesses this particular episodic memory. It is sort of like a semantic-episodic PGP key with your private key being stored in your brain. Only if you are the owner of the memory is the cue likely to remind you of the associates. We have been exploring ways of using memory models to cue users to generate good fastwords that allow for a sort of memorability meter along with a security (guessability) meter. The interesting thing is that the type of fastword most likely to be remembered is also the type which is most secure, and we can use the memory models to help people to generate fastwords that are likely to be easily remembered, but very difficult to guess by an adversary. Mike: Memory research and passwords Op Ed Read about Fastwords NPR: Hunting for a password that only you will know 
|
